
Despite recent advancements in text-to-image diffusion models facilitating various image editing techniques, complex text prompts often lead to an oversight of some requests due to a bottleneck in processing text information. To tackle this challenge, we present Ground-A-Score, a simple yet powerful model-agnostic image editing method by incorporating grounding during score distillation. This approach ensures a precise reflection of intricate prompt requirements in the editing outcomes, taking into account the prior knowledge of the object locations within the image. Moreover, the selective application with a new penalty coefficient and contrastive loss helps to precisely target editing areas while preserving the integrity of the objects in the source image. Both qualitative assessments and quantitative analyses confirm that Ground-A-Score successfully adheres to the intricate details of extended and multifaceted prompts, ensuring high-quality outcomes that respect the original image attributes.
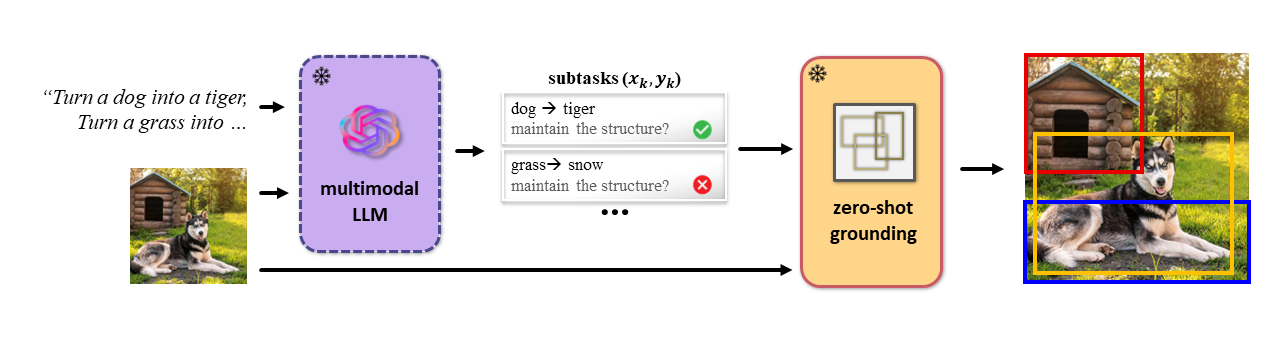
We leverage the prior knowledge from the multimodal LLM and the zero-shot grounding model to break down the user request into multiple image editing subtasks for a single entity.
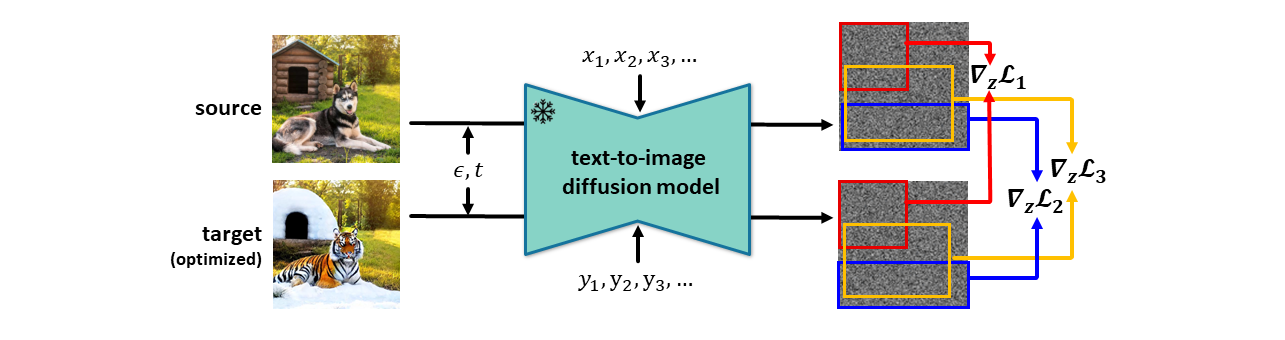
A pre-trained text-to-image diffusion model is used for each subtask to obtain a corresponding gradient for the source image. These gradients are masked and aggregated to get a total gradient that is efficient and stable.

